游戏人工智能 读书笔记 (六) AI算法简介——演化算法
作者:苏博览 腾讯IEG高级研究员
| 导语 遗传算法(Genetic Algorithm,简称GA)是一种最基本的演化算法(Evolutionary Algorithm),它是模拟达尔文生物进化理论的一种优化模型,是全局的随机优化算法(Randomized Global Optimization Algorithms)。遗传算法中从一个或多个初始策略开始(称为初代), 每一代成为一个种群, 种群中每个个体都是解空间上的一个可行解,通过模拟生物的进化过程,随机的改变部分策略(突变)或者随机的合并多个策略(杂交)来得的新的策略(下一代),从而在解空间内搜索最优解。
作者: fled
本文内容包含以下章节:
Chapter 2 AI Methods
Chapter 2.4 Evolutionary Computation
Chapter 2.8 Hybrid Algorithm: Neuroevolution
本书英文版: Artificial Intelligence and Games - A Springer Textbook4
从前面一篇文章可以看到,树搜索算法是从初始状态开始,基于合法的动作来生成一颗树,树的叶子节点是终止状态,然后通过搜索,来找到一条最佳的从初始状态到终止状态的路径。而优化算法(optimization algorithm)则是基于任务来构造一个目标函数(Objective function),然后在整个解法空间中,来寻找一个可以最大化目标函数的效用(Utility)的策略(Strategy)。
一. Local Search: 爬山算法和模拟退火
Local Search 是其中最简单的一种优化算法,顾名思义,假设一个solution是N维向量,那么当前给定一个solution s_0 (N维空间上的一个点), 我们就在 s_0 附近的区间内寻找一个更好的解法 s_1 ,然后再从 s_1 出发寻找下一个解法。Local Search在每一代都只保留一个解法,每次都从该解法出发去找寻下一个解法。这个方式其实有点像爬山的过程,因此又叫hill climber算法。但是如下图所示,这个算法很可能会终止在一个local maximum里面。
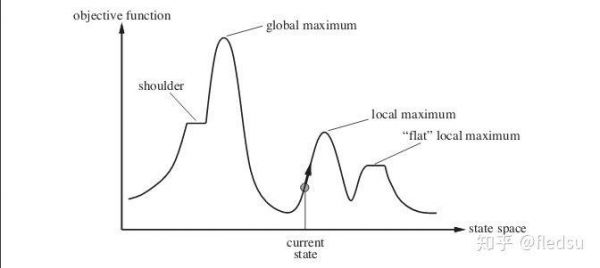
一维 Hill Climber算法,从当前的状态出发往更好的状态转移(通常是基于梯度的方向),但是到达了一个local maximumn或者半山腰的时候,会发现没法继续找到更好的状态。
为了解决Local Maximum的问题,人们参考突变(mutation)的思想设计了随机爬山算法(Randomized Hill Climber), 从当前的状态 s_0 开始,不再是基于梯度的方式,而是随机的改变 s_0 的某些维度来得到一个新的状态 s' ,看是否能到达一个更好的状态,这样,上图中的状态就有机会向左边转变,然后跑到global maximum去。这个算法还是要求突变后的状态要比原理的状态好,因此也不能保证一定能找到最优解。
另外一种方法是模拟退火算法(Simulated Annealing), 和爬山算法相比,它的搜索过程引入了随机因素。这个退火也是来自于对材料退火的原理。
模拟退火来自冶金学的专有名词退火。退火是将材料加热后再经特定速率冷却,目的是增大晶粒的体积,并且减少晶格中的缺陷。材料中的原子原来会停留在使内能有局部最小值的位置,加热使能量变大,原子会离开原来位置,而随机在其他位置中移动。退火冷却时速度较慢,使得原子有较多可能可以找到内能比原先更低的位置。 https://zh.wikipedia.org/wiki/%E6%A8%A1%E6%8B%9F%E9%80%80%E7%81%AB
我们如果把一个解法(solution)看作空间中的一个原子,那么“加热”的过程相当于随机的改变当前的解法,然后得到一个新的解法。这个时候我们就基于Metropolis准则来判断是否接受新解法:1. 如果新的解法比原来的解法好,我们会接受该解法;2. 如果新的解法比原来的解法差,我们还是有一定的概率来接受新的解法。这个概率是由两个参数决定的: 1. 两个解法的Fitting Function的差值(“能量差”) 和 2. 当前的“温度”(也即是算法的迭代次数)。 因此如果两个解法的差距不大,接受新解法的概率越大;在算法迭代开始的时候,接受新解法的概率也更大一些。参考热力学定律,在温度为 T 时,出现能量差为 Delta U的降温的概率为 exp(-Delta U/T) , 这个也是我们是否接受新解法的概率。整个模拟退火的伪代码如下:
def simulated_anneling(): s = s0 #initial solution T = T0 #initial temperature while T > Tmin and E(s) > Emax: s_n = random_new_state(s) #get a new state based on s if E(s_n) > E(s): #get the "energy"(fitness score) of solution s = s_n else: dE = abs(E(s_n) - E(s)) if random(0,1) < exp(dE/T): #accept new solution s = s_n T = r * T # reduce the temperature, 0<r<1
模拟退火算法与初始值无关,算法求得的解与初始解状态S(是算法迭代的起点)无关;模拟退火算法具有渐近收敛性,已在理论上被证明是一种以概率1收敛于全局最优解的全局优化算法;模拟退火算法具有并行性。 https://zh.wikipedia.org/wiki/%E6%A8%A1%E6%8B%9F%E9%80%80%E7%81%AB
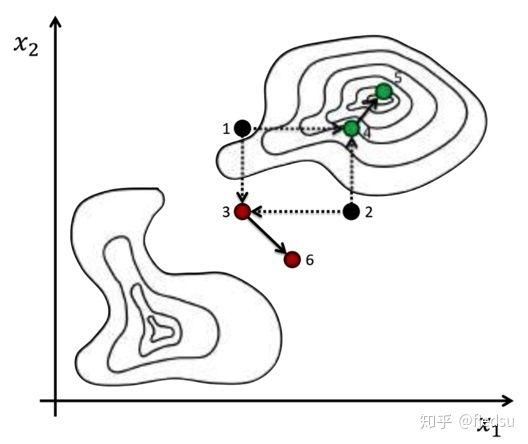
演化算法的例子:1和2 crossover 生成3 和4, 3突变生成6, 4突变生成5
二. 遗传算法(Genetic Algorithm)
而如果我们初始化的时候,不是只初始化一个种子,而是同时保留多个不同的solutions,同时更新。每次优化的时候,也不是只保留一个新的解法,而是丢掉比较差的算法,但保留多个不同的解法,我们就得到了演化算法的基本思路。
遗传算法(Genetic Algorithm,简称GA)是一种最基本的演化算法(Evolutionary Algorithm),它是模拟达尔文生物进化理论的一种优化模型,是全局的随机优化算法(Randomized Global Optimization Algorithms)。遗传算法中从一个或多个初始策略开始(称为初代), 每一代成为一个种群, 种群中每个个体都是解空间上的一个可行解,通过模拟生物的进化过程,随机的改变部分策略(突变)或者随机的合并多个策略(杂交)来得的新的策略(下一代),从而在解空间内搜索最优解。遗传算法一般是通过Utility Function(或者在演化算法中通常叫Fitness Function)来保留当前更好的策略,而去除一些较差的策略(天择),有些算法还会随机的消灭掉部分的策略,而不管它是不是当前比较好的策略(来模拟自然界中的灾变,比如毁灭恐龙的小行星 和 打个响指的灭霸)。

应该很快某个算法框架的某个模块就叫Thanos了~~
在有些时候,我们的解法是有一定的限制(constraint)的,因此随机的crossover和mutation可能都会产生很多的不合法的解法。但是如果我们给演化的过程增加限制,去除很多的不合法解法的话,很可能我们的演化算法没法找到一个很好的solution,因为初期大部分的演化solution都被杀死了。因此人们提出了feasible-infeasible 2-population(FI-2pop)算法来缓解这个问题。在演化的过程中,算法维护两个队列,一个队列里只包含可用的解法(feasible),另一个队列则没有限制(infeasible),只要infeasible的队列中产生了可用解法(feasible solution),这个解法就会放入feasible的队列中。通过这样的方式,FI-2pop找到不同的feasible solution的概率增大了。
三. 进化策略(Evolution Strategy)
在传统的遗传算法中,一般是使用二进制编码(DNA)来编码种群中的个体的,这样最大的好处是做crossover 和 Mutation特别方便,mutation 就是某个位置上的0变成1 或者 1变成0, crossover就可以简单的定义为异或,或者随机选取父辈对应位置的编码就可以了。
但是在很多场景中,个体的特性不是固定的,而是服从某种分布的。比如人的能力,就不是一个固定值,而是会在一定的范围内波动。通过我们假设这个分布是高斯分布,这样我们就可以用均值和方差来表示这个分布了,因此和GA相比,进化策略(ES)的算法表示是两组实数值的编码(DNA),一组代表该维的均值,另一组代表方差。这样在进化的时候(crossover 和 mutation)也和GA稍有不同,crossover相当于合并两个高斯分布,通常可以考虑合并高斯分布的均值;mutation则可以改变高斯分布的方差。这个改变的幅度也可以用一个权重来控制。基于不同的合并策略,我们可以得到不同的ES的变种。
四. 多目标演化算法
另一方面,演化算法很可能是多目标的(multiobjective),演化算法要找到一个帕累托最优(Pareto Optimality)的solution,这个解法要满足“不可能再改善某些目标的境况,而不使任何其他的目标受损”。通常来说这个解法不是唯一的。在游戏AI的设计中,我们经常会碰到这样的问题,比如在设计策略游戏的过程中,我们希望设计各方的兵种是各有特色的,同时各方的实力又比较平衡的,这方面的比较好的例子有《星际争霸》。
通常这样的多目标的优化问题很难用数学的方法来进行优化,但是演化算法在这上面比较有优势。 因为演化算法每代都随机的全局搜索,可以产生多个候选的解,构成近似问题的Pareto最优解集;同时在种群中,不同的个体可以满足不同类型的目标函数和约束。常用的多目标演化算法有GA, 蚁群算法等,这里就不详细的阐述了。

五. 神经进化算法(Neuroevolution)
前面几篇文章分别讨论了不同类型的AI算法。但是在实际应用中,我们经常会把不同的AI技术混在一起使用,以期获得更好的效果。例如,我们可以用演化算法(GA)来学习行为树的参数,我们也可以像Deepmind那样用神经网络来对MCTS做更有效的剪枝(Pruning)。我们通常称这样的算法为混合算法(Hybrid algorithm)。这里把神经网络和演化算法结合的混合算法就叫做:Neuroevolution。
神经演化算法(Neuroevolution)主要是用演化学习的思想来调整神经网络的结构和权重。通常我们是用梯度下降的方法来更新神经网络的结构,但是如果我们不能很好的用监督学习的方法来训练神经网络的时候(例如训练的神经网络的loss function没法微分(differentiable),或者我们没有一个很好的标注的训练样本),这个时候我们就要考虑演化学习的框架了。这个在游戏AI中经常能够遇到,比如我们很难定义一个行为是不是好的(如王者荣耀中,一个英雄在某个场景中使用某个技能是好的还是坏的)。而在演化学习的框架下,我们只需要考虑一个对Solution(某个训练好的神经网络)的度量(fitness function)。其中基于NEAT算法(NeuroEvolution of Augmenting Topologies 增强拓扑的神经网络进化), 人们开发了可以玩马里奥的AI,具体的代码实现可以看下面的链接。
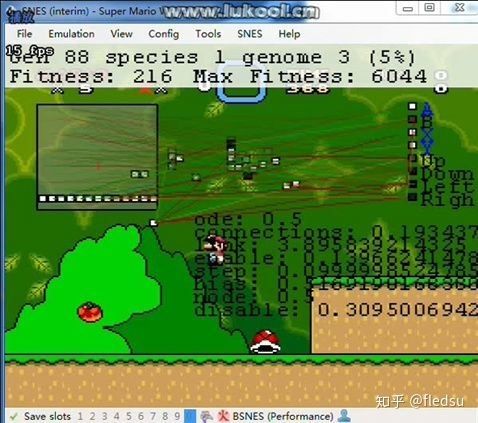
NeuroEvolution with MarI/Oglenn-roberts.com

当然,演化学习需要在每一代都保留多个可用的模型,然后在随机进行crossover 或者 mutation。可想而知,这是一件非常耗费计算能力的事情,所以目前为止能得到的网络规模也不大、完成的任务也不够复杂。不过去年底的时候, Uber AI Lab一连发了5篇文章来证明Neuroevolution 也可以高效的训练大规模的神经网络。这里就不具体的描述其算法啦,有兴趣的可以到Uber 公开的Github去看它的源码和论文:
Welcoming the Era of Deep Neuroevolutioneng.uber.com
uber-common/safemutationsgithub.com

相关知识
游戏人工智能 读书笔记 (六) AI算法简介——演化算法
算法在游戏开发中的应用:游戏AI、游戏机制与游戏平衡性的实现
Python中的策略更新算法优化:提升游戏AI性能的关键技术
人工智能与游戏策略:未来的技术趋势1.背景介绍 随着人工智能技术的不断发展,游戏策略设计也逐渐走向智能化。人工智能(AI
人工智能在游戏领域的应用:从AI对手到游戏设计1.背景介绍 游戏领域的人工智能(AI)应用已经存在很多年,从最基本的游戏
少前云图计划算法效率提升攻略
即时战略游戏中的高实用性寻路算法——A*算法解析
游戏编程算法与技巧
AI人工智能游戏辅助工具:全功能脚本解决方案,覆各类游戏辅助需求
人工智能游戏的音效与音乐设计1.背景介绍 人工智能(Artificial Intelligence, AI)游戏的音效与
推荐资讯






- 1老六爱找茬美女的烦恼怎么过- 4999
- 2博德之门3黄金雏龙法杖怎么得 4869
- 3《大侠立志传》剿灭摸金门任务 4312
- 4代号破晓官方正版角色介绍 4023
- 5赛马娘锻炼到底的伙伴支援卡事 3802
- 6闪烁之光11月兑换码大全20 3774
- 7原神原海异种刷怪路线-原神原 3547
- 8爆梗找茬王厕所特工怎么通关- 3542
- 9《我的世界》领地删除指令是什 3440
- 10原神开局星落湖怎么出去 原神 3426


