【ML】英雄联盟对局胜负预测任务
本样例以英雄联盟对局胜负预测任务为基础,简单展示了机器学习任务的大致流程,为机器学习入门者提供参考。
任务介绍英雄联盟(League of Legends,LoL)是一个多人在线竞技游戏,由拳头游戏(Riot Games)公司出品。在游戏中,每位玩家控制一位有独特技能的英雄,红蓝两支队伍各有五位玩家进行对战,目标是摧毁对方的基地水晶。水晶有多座防御塔保护,通常需要先摧毁一些防御塔再摧毁水晶。玩家所控制的英雄起初非常弱,需要不断击杀小兵、野怪和对方英雄来获得金币、经验。经验可以提升英雄等级和技能等级,金币可以用来购买装备提升攻击、防御等属性。对战过程中一般没有己方单位在附近的地点是没有视野的,即无法看到对面单位,双方可以通过使用守卫来监视某个地点,洞察对面走向、制定战术。
本数据集来自Kaggle,包含了9879场钻一到大师段位的单双排对局,对局双方几乎是同一水平。每条数据是前10分钟的对局情况,每支队伍有19个特征,红蓝双方共38个特征。这些特征包括英雄击杀、死亡,金钱、经验、等级情况等等。一局游戏一般会持续30至40分钟,但是实际前10分钟的局面很大程度上影响了之后胜负的走向。作为最成功的电子竞技游戏之一,对局数据、选手数据的量化与研究具有重要意义,可以启发游戏将来的发展和改进。本任务是希望构建机器学习模型根据已有的对局前10分钟特征信息,预测最后获胜方是蓝色方还是红色方。
pandas是数据分析和处理常用的工具包,非常适合处理行列表格数据。numpy是数学运算工具包,支持高效的矩阵、向量运算。matplotlib和seaborn是作图常用工具包,其中seaborn是基于matplotlib的高级封装,使用一般更简便。sklearn是机器学习常用工具包,包括了一些已经实现好的简单模型和一些常用数据处理方法、评价指标等函数。
import pandas as pd # 数据处理 import numpy as np # 数学运算 import matplotlib.pyplot as plt # 作图 import seaborn as sns # 作图 from sklearn.linear_model import LogisticRegression # 逻辑回归 from sklearn.preprocessing import MinMaxScaler # 归一化函数 from sklearn.model_selection import train_test_split, cross_validate # 划分数据集函数 from sklearn.metrics import accuracy_score # 准确率函数 RANDOM_SEED = 2020 # 固定随机种子 123456789 读入数据
假设数据文件放在./data/目录下,标准的csv文件可以用pandas里的read_csv()函数直接读入。文件共有40列,38个特征(红蓝方各19),1个标签列(blueWins),和一个对局标号(gameId)。对局标号不是标签也不是特征,可以舍去。
csv_data = './data/high_diamond_ranked_10min.csv' # 数据路径 data_df = pd.read_csv(csv_data, sep=',') # 读入csv文件为pandas的DataFrame data_df = data_df.drop(columns='gameId') # 舍去对局标号列 123 数据概览
对于一个机器学习问题,在拿到任务和数据后,首先需要观察数据的情况,比如我们可以通过.iloc[0]取出数据的第一行并输出。不难看出每个特征都存成了float64浮点数,该对局蓝色方开局10分钟有小优势。同时也可以发现有些特征列是重复冗余的,比如blueGoldDiff表示蓝色队金币优势,redGoldDiff表示红色方金币优势,这两个特征是完全对称的互为相反数。blueCSPerMin是蓝色方每分钟击杀小兵数,它乘10就是10分钟所有小兵击杀数blueTotalMinionsKilled。在之后的特征处理过程中可以考虑去除这些冗余特征。
另外,pandas有非常方便的describe()函数,可以直接通过DataFrame进行调用,可以展示每一列数据的一些统计信息,对数据分布情况有大致了解,比如blueKills蓝色方击杀英雄数在前十分钟的平均数是6.14、方差为2.93,中位数是6,百分之五十以上的对局中该特征在4-8之间,等等。
print(data_df.iloc[0]) # 输出第一行数据 data_df.describe() # 每列特征的简单统计信息 12
blueWins 0.0 blueWardsPlaced 28.0 blueWardsDestroyed 2.0 blueFirstBlood 1.0 blueKills 9.0 blueDeaths 6.0 blueAssists 11.0 blueEliteMonsters 0.0 blueDragons 0.0 blueHeralds 0.0 blueTowersDestroyed 0.0 blueTotalGold 17210.0 blueAvgLevel 6.6 blueTotalExperience 17039.0 blueTotalMinionsKilled 195.0 blueTotalJungleMinionsKilled 36.0 blueGoldDiff 643.0 blueExperienceDiff -8.0 blueCSPerMin 19.5 blueGoldPerMin 1721.0 redWardsPlaced 15.0 redWardsDestroyed 6.0 redFirstBlood 0.0 redKills 6.0 redDeaths 9.0 redAssists 8.0 redEliteMonsters 0.0 redDragons 0.0 redHeralds 0.0 redTowersDestroyed 0.0 redTotalGold 16567.0 redAvgLevel 6.8 redTotalExperience 17047.0 redTotalMinionsKilled 197.0 redTotalJungleMinionsKilled 55.0 redGoldDiff -643.0 redExperienceDiff 8.0 redCSPerMin 19.7 redGoldPerMin 1656.7 Name: 0, dtype: float64
12345678910111213141516171819202122232425262728293031323334353637383940 blueWinsblueWardsPlacedblueWardsDestroyedblueFirstBloodblueKillsblueDeathsblueAssistsblueEliteMonstersblueDragonsblueHeralds...redTowersDestroyedredTotalGoldredAvgLevelredTotalExperienceredTotalMinionsKilledredTotalJungleMinionsKilledredGoldDiffredExperienceDiffredCSPerMinredGoldPerMincount9879.0000009879.0000009879.0000009879.0000009879.0000009879.0000009879.0000009879.0000009879.0000009879.000000...9879.0000009879.0000009879.0000009879.0000009879.0000009879.0000009879.0000009879.0000009879.0000009879.000000mean0.49903822.2882882.8248810.5048086.1839256.1376666.6451060.5499540.3619800.187974...0.04302116489.0414016.92531617961.730438217.34922651.313088-14.41411133.62030621.7349231648.904140std0.50002418.0191772.1749980.5000023.0110282.9338184.0645200.6255270.4805970.390712...0.2169001490.8884060.3053111198.58391221.91166810.0278852453.3491791920.3704382.191167149.088841min0.0000005.0000000.0000000.0000000.0000000.0000000.0000000.0000000.0000000.000000...0.00000011212.0000004.80000010465.000000107.0000004.000000-11467.000000-8348.00000010.7000001121.20000025%0.00000014.0000001.0000000.0000004.0000004.0000004.0000000.0000000.0000000.000000...0.00000015427.5000006.80000017209.500000203.00000044.000000-1596.000000-1212.00000020.3000001542.75000050%0.00000016.0000003.0000001.0000006.0000006.0000006.0000000.0000000.0000000.000000...0.00000016378.0000007.00000017974.000000218.00000051.000000-14.00000028.00000021.8000001637.80000075%1.00000020.0000004.0000001.0000008.0000008.0000009.0000001.0000001.0000000.000000...0.00000017418.5000007.20000018764.500000233.00000057.0000001585.5000001290.50000023.3000001741.850000max1.000000250.00000027.0000001.00000022.00000022.00000029.0000002.0000001.0000001.000000...2.00000022732.0000008.20000022269.000000289.00000092.00000010830.0000009333.00000028.9000002273.2000008 rows × 39 columns
特征处理传统的机器学习模型大部分都是基于特征的,因此特征工程是机器学习中非常重要的一步。有时构造一个好的特征比改进一个模型带来的提升更大。这里简单展示一些特征处理的例子。首先,上面提到,特征列中有些特征信息是完全冗余的,会给模型带来不必要的计算量,可以去除。其次,相比于红蓝双方击杀、助攻的绝对值,可能双方击杀英雄的差值更能体现出当前对战的局势。因此,我们可以构造红蓝双方对应特征的差值。数据文件中已有的差值是金币差GoldDiff和经验差ExperienceDiff,实际上每个对应特征都可以构造这样的差值特征。
drop_features = ['blueGoldDiff', 'redGoldDiff', 'blueExperienceDiff', 'redExperienceDiff', 'blueCSPerMin', 'redCSPerMin', 'blueGoldPerMin', 'redGoldPerMin'] # 需要舍去的特征列 df = data_df.drop(columns=drop_features) # 舍去特征列 info_names = [c[3:] for c in df.columns if c.startswith('red')] # 取出要作差值的特征名字(除去red前缀) for info in info_names: # 对于每个特征名字 df['br' + info] = df['blue' + info] - df['red' + info] # 构造一个新的特征,由蓝色特征减去红色特征,前缀为br 12345678 特征相关性
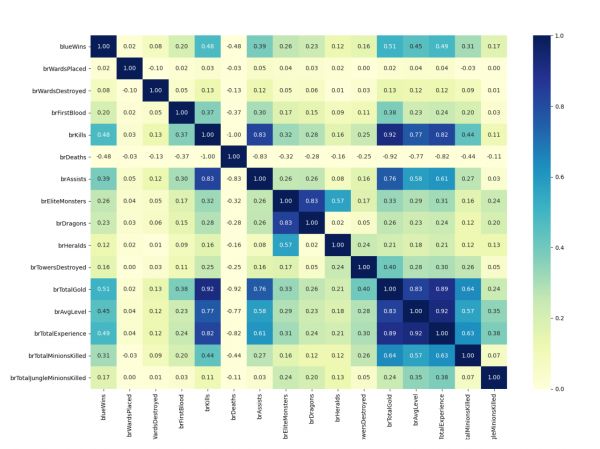
为了了解每个特征的重要性或者特征之间的关联性,可以求两两特征或特征和标签之间的相关性。本样例以红蓝双方的差值特征为例,求了两两特征之间的pearson相关系数,并可视化为热力图矩阵。相关系数的值在-1到1之间,越接近1表示正相关性越强,越接近-1表示负相关性越强。在相关性矩阵中,不难看出对角都是1,是因为一个特征和自身的相关性自然是最强正相关。矩阵是对称的,因为特征A和特征B的相关性等价于特征B与特征A的相关性。从第一行(或列)可以看出哪些特征和标签blueWins相关。最强正相关性的特征是队伍金币差brTotalGold,和标签的正相关性表示该特征值越大,标签值一般情况下也越大(越可能为1),这很自然因为蓝色方前十分钟的金币优势越大,最终获胜的可能性也越大。特征和特征之间的相关性也可以从矩阵中看出来,比如右下角蓝色的一块包括队伍金币差brTotalGold、队伍平均等级差brAvgLevel和队伍总经验差brTotalExperience三个特征,另外加上击杀英雄差brKills四个特征,它们两两特征之间的正相关性都非常高,这也很好理解,因为击杀英雄多了,金币和经验就多了,等级也高了,获胜的概率也高了,因此和标签的正相关性也都较高。但是一般我们不希望高相关性的特征太多,因为希望不同特征能覆盖不同的信息,而不是重复冗余的信息,例如之前去除的是完全冗余的相关性为1的特征。
plt.figure(figsize=(16, 12)) # 设置图像大小 # 获得相关性矩阵,pandas的DataFrame有直接的函数 corr_matrix = df[[c for c in df.columns if c == 'blueWins' or c.startswith('br')]].corr() cg = sns.heatmap(corr_matrix, cmap='YlGnBu', annot=True, fmt='.2f', vmin=0); # 用seaborn作热力图 1234
构建机器学习模型前要构建训练和测试的数据集。在本例中首先需要分开标签和特征,标签是不能作为模型的输入特征的,就好比作业和试卷答案不能在做题和考试前就告诉学生。另外比较重要的一点是本任务中特征值的范围差距很大,有些特征大于一万,有些特征一般小于10,对于有些模型包括神经网络模型,可能会不利于参数学习,增加训练难度。因此通常会将特征值标准化到0-1之间,比如本例中我们使用sklearn提供的MinMaxScaler,将所有样本的某一列特征,最大值映射到1,最小值映射到0。测试一个模型在一个任务上的效果至少需要训练集和测试集,训练集用来训练模型的参数,好比学生做作业获得知识,测试集用来测试模型效果,好比期末考试考察学生学习情况。测试集的样本不应该出现在训练集中,否则会造成模型效果估计偏高,好比考试时出的题如果是作业题中出现过的,会造成考试分数不能准确衡量学生的学习情况,估计值偏高。划分训练集和测试集有多种方法,下面首先介绍的是随机取一部分如20%作测试集,剩下作训练集。sklearn提供了相关工具函数train_test_split。sklearn的输入输出一般为numpy的array矩阵,需要先将pandas的DataFrame取出为numpy的array矩阵。
all_y = df['blueWins'].values # 所有原始特征值,pandas的DataFrame.values取出为numpy的array矩阵 all_x = df[df.columns[1:]].values # 所有标签数据 scaler = MinMaxScaler().fit(all_x) # 需要对特征作归一化,sklearn提供了相关工具 all_x = scaler.transform(all_x) # 将特征归一化到01 # 划分训练集和测试集 x_train, x_test, y_train, y_test = train_test_split(all_x, all_y, test_size=0.2, random_state=RANDOM_SEED) all_y.shape, all_x.shape, x_train.shape, x_test.shape, y_train.shape, y_test.shape # 输出数据行列信息 1234567
((9879,), (9879, 45), (7903, 45), (1976, 45), (7903,), (1976,)) 1 模型训练和测试
本例以sklearn中的逻辑回归LogisticRegression为例展示模型的训练和测试过程,它是个线性分类器。sklearn中还有很多其他分类器如KNN、决策树、SVM等等。调用非常简单,给定一些超参数如最大迭代轮次等初始化一个LogisticRegression()类之后,可以通过fit()函数进行训练,predict()函数可以用来对样本进行预测输出预测值。本例采用准确率进行评价sklearn中有accuracy_score()函数帮助计算准确率。如果效果不好,可以尝试调整模型的超参数,如最大训练轮次、学习速率、正则化项权重等。
LR = LogisticRegression(random_state=RANDOM_SEED, verbose=1, max_iter=1000) # 初始化逻辑回归模型 LR.fit(x_train, y_train) # 在训练集上训练 p_test = LR.predict(x_test) # 在测试集上预测,获得预测值 print(p_test) # 输出预测值 test_acc = accuracy_score(p_test, y_test) # 将测试预测值与测试集标签对比获得准确率 print('accuracy: {:.4}'.format(test_acc)) # 输出准确率 123456
[0 1 0 ... 0 1 1] accuracy: 0.7328 [Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers. [Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s finished 123456 交叉验证
在数据量不是很大的情况下,测试集可能也不够大,不能准确估计所得到的模型在未见样本上的效果,并且单次训练测试可能有偏差,一般需要重复多次训练测试取平均值。一种常用的重复实验的方式是交叉验证,它将整个数据集划分为K份,每次取其中一份作为测试集,其他K-1份作为训练集,取K次测试结果的平均作为最终模型的准确率。sklearn同样提供了非常方便的交叉验证的接口cross_validate,输入定义好的模型,所有训练数据以及折数K,可以得到每折训练测试的结果。例如下面代码中cv=5表示5折交叉验证。
LR = LogisticRegression(random_state=RANDOM_SEED, verbose=0, max_iter=1000) # 定义逻辑回归模型 scores = cross_validate(LR, all_x, all_y, cv=5, scoring=('accuracy'), return_train_score=True) # 5折交叉验证 print(scores) # 交叉验证的结果,是个python的dict,存有训练时间fit_time、测试时间score_time,测试准确率test_score,训练准确率train_score print('average accuracy: {:.4f}'.format(np.mean(scores['test_score']))) # 输出多折的测试准确率均值 1234
{'fit_time': array([0.15559244, 0.16526341, 0.18318272, 0.16132855, 0.1458261 ]), 'score_time': array([0.00039506, 0.0004127 , 0.00040436, 0.00039434, 0.00039506]), 'test_score': array([0.7388664 , 0.72975709, 0.73279352, 0.7388664 , 0.72607595]), 'train_score': array([0.73326585, 0.73351892, 0.73415159, 0.73073516, 0.73380567])} average accuracy: 0.7333 12 模型参数
大部分模型都有一些参数,会根据训练集训练出合适的值。在sklearn中,训练完成后可以输出模型参数进行查看。例如在逻辑回归模型中比较重要的参数是每个特征的权重coef_。在本例中,对应特征的权重绝对值越大,表示对分类预测的贡献越大。正值表示该特征值越大越偏向预测蓝色方胜利,相反的负值表示偏向预测红色方胜利。
LR.fit(x_train, y_train) # 训练模型 print(LR.classes_.shape, LR.classes_) # 类别个数 print(LR.n_iter_.shape, LR.n_iter_) # 训练执行轮次 print(LR.coef_.shape, LR.coef_) # 特征权重 print(LR.intercept_.shape, LR.intercept_) # 分类截距 12345
(2,) [0 1] (1,) [193] (1, 45) [[-0.59737104 0.06575039 0.02090261 0.26153071 -0.13618641 -0.17784935 0.10299402 0.16211285 0.04387518 -0.31606273 2.80851846 0.2661344 1.20491802 -0.00915835 0.42522354 -0.58995972 -0.06294822 -0.0257645 -0.13618641 0.26153071 -0.06571498 -0.08792058 -0.1457875 -0.03005367 0.35012894 -2.48974911 -0.20118816 -1.17832489 0.06173208 0.15223858 0.02363155 0.06900422 0.02090261 0.26264013 -0.26750203 -0.07164915 0.09302635 0.15151922 0.03453348 -0.32903876 2.91792133 0.31544563 1.61055321 -0.05467035 0.18671295]] (1,) [-3.06028514] 1234567891011 可视化特征权重
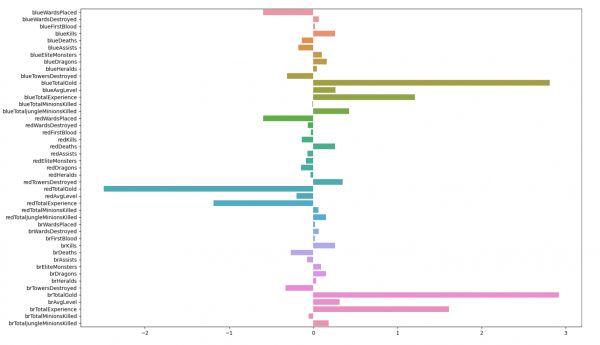
研究模型的参数可以帮助我们理解模型分类预测的依据,对结果作解释。例如我们将每个特征对应的权重用柱状图表示出来,见下图。不难看到,和之前的分析结果相一致,最重要的特征包括蓝色方队伍金币blueTotalGold、红色方队伍金币redTotalGold、队伍金币差brTotalGold、队伍经验差brTotalExperience等,蓝色队伍金币经验领先越大,模型越可能预测蓝色方胜利。
plt.figure(figsize=(8,15)) sns.barplot(x=LR.coef_[0], y=df.columns[1:]) 12
一个完整的机器学习任务包括:确定任务、数据分析、特征工程、数据集划分、模型设计、模型训练和效果测试、结果分析和调优等多个阶段,本案例以英雄联盟游戏胜负预测任务为例,给出了每个阶段的一些简单例子,帮助大家入门机器学习,希望大家有所收获!
相关知识
英雄联盟手游冠军预测应该怎么选择
英雄联盟s13冠军预测
英雄联盟灵能特工隐藏任务完成攻略
英雄联盟手游kda第二天任务
《英雄联盟》2022战斗之夜第三周任务时间
《英雄联盟》2023排位挂机处罚一览
《王者荣耀》新英雄预测
《英雄联盟手游》主动使用两次鞋子任务策略
英雄联盟执事通行证任务怎么做-lol通行证任务攻略
《英雄联盟》手游击鼓赛龙舟活动怎么玩
推荐资讯






- 1老六爱找茬美女的烦恼怎么过- 5025
- 2博德之门3黄金雏龙法杖怎么得 4885
- 3《大侠立志传》剿灭摸金门任务 4330
- 4代号破晓官方正版角色介绍 4047
- 5赛马娘锻炼到底的伙伴支援卡事 3818
- 6闪烁之光11月兑换码大全20 3800
- 7爆梗找茬王厕所特工怎么通关- 3563
- 8原神原海异种刷怪路线-原神原 3560
- 9《我的世界》领地删除指令是什 3476
- 10原神开局星落湖怎么出去 原神 3448


